



-
How to audit what AI is saying about your brand in 30 minutes
by Rajiv Singha
AI visitors convert at 4.4x the rate of traditional organic traffic. And AI search traffic is up 527% year on …
Continue reading “How to audit what AI is saying about your brand in 30 minutes”
-
Sustainable vs Green Marketing: Key Differences and When to Use Each
by Tapam Jaswal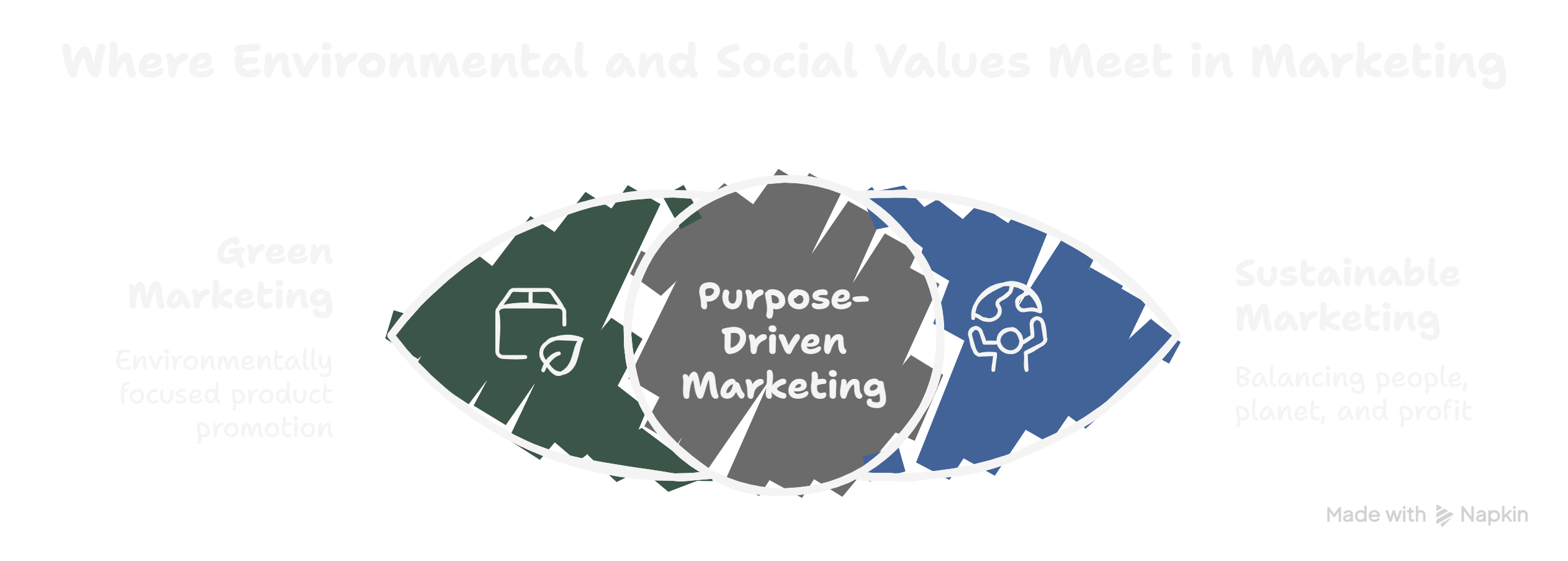
You’ll see the terms “green marketing” and “sustainable marketing” used interchangeably online. They are not the same. Here’s a side-by-side …
Continue reading “Sustainable vs Green Marketing: Key Differences and When to Use Each”
-
Why Feed-Only PMax Campaigns Are the Smartest Choice for Ecommerce stores
by Yash Pal
If you sell products online, you have probably heard about Google’s Performance Max (PMax) campaigns. They have been a hot …
Continue reading “Why Feed-Only PMax Campaigns Are the Smartest Choice for Ecommerce stores”
-
Email Marketing Without Fatiguing Conscious Consumers
by Charanjeev Singh
How to build trust, reduce inbox overload, and engage with intention Email marketing is a powerful tool. It lets …
Continue reading “Email Marketing Without Fatiguing Conscious Consumers”
-
How to Market Vegan Products Without Preaching (or Losing Sales)
by Tapam Jaswal
Marketing vegan products isn’t just about talking to people who already follow a vegan lifestyle. It’s also about connecting with …
Continue reading “How to Market Vegan Products Without Preaching (or Losing Sales)”
-
Vegan SEO: Optimizing Organic Visibility for Vegan Brands
by Tapam Jaswal
More people than ever are interested in vegan products and services. If you run a vegan brand, ensuring customers can …
Continue reading “Vegan SEO: Optimizing Organic Visibility for Vegan Brands”